needle-in-a-needlestack
Sonnet 3.5 Does Much Better at NIAN Than Sonnet 3.0
by Tom Burns
Needle in a Needlestack is a new benchmark to measure how well LLMs pay attention to the information in their context
window. NIAN creates a prompt that includes thousands of limericks and the prompt asks a question about one limerick
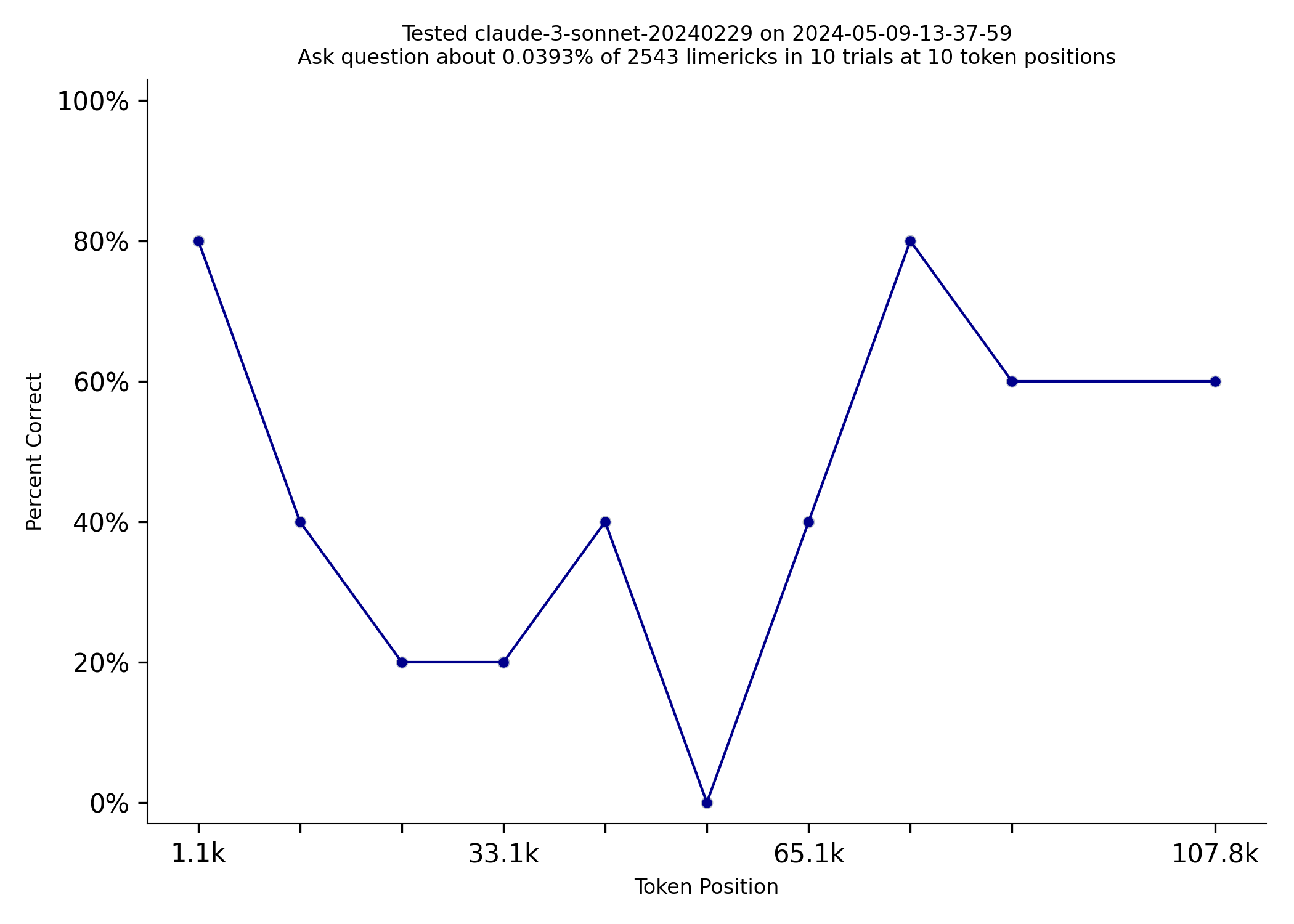
at a specific location. Here is an example prompt that includes 2500ish limericks. I tested the just released
Sonnet 3.5 on NIAN, and it did much better than 3.0:
 |
 |
|---|---|
| Sonnet 3.0 | Sonnet 3.5 |
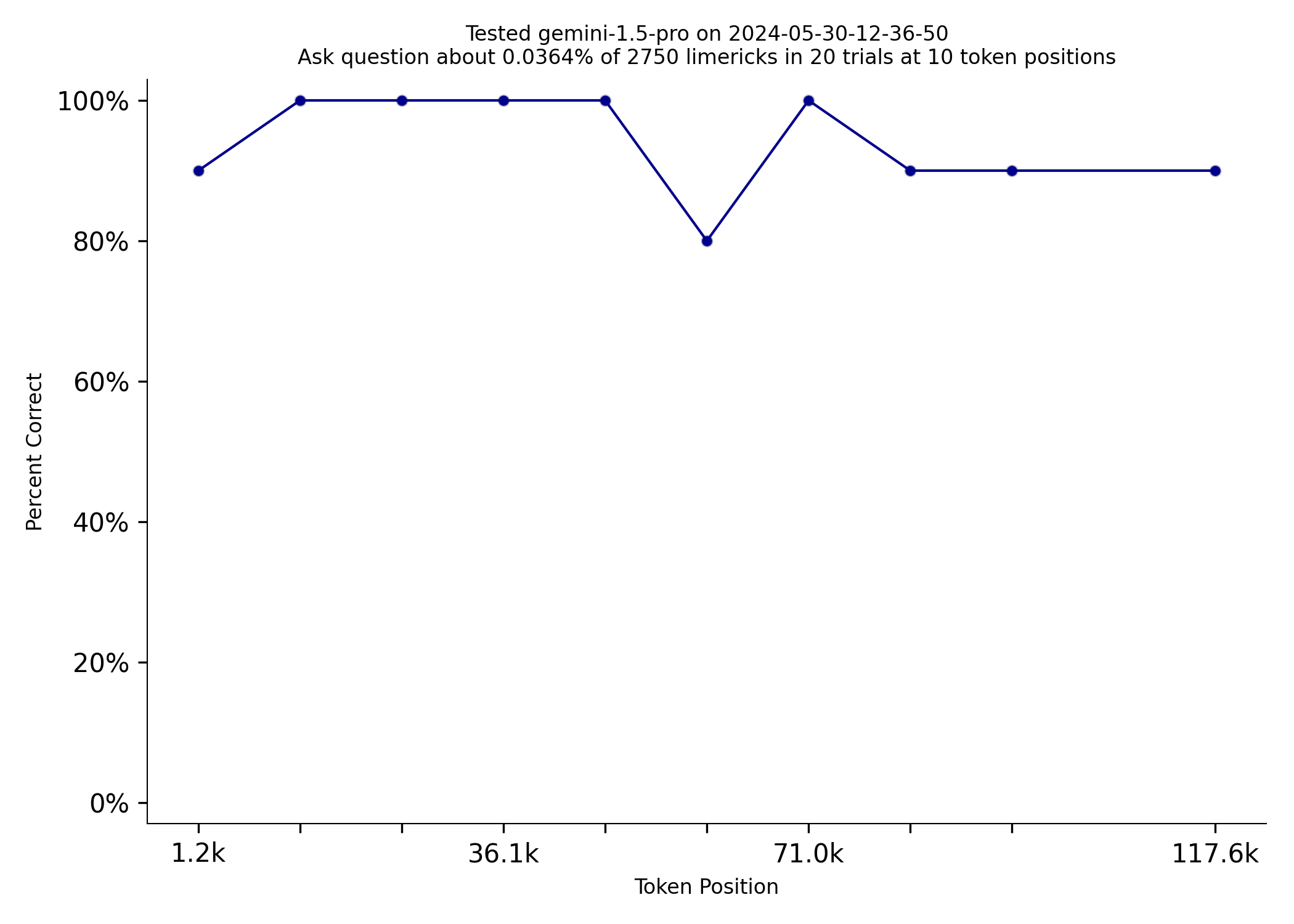
However, Google’s Gemini Pro costs about the same as Sonnet 3.5, but Gemini does dramatically better on NIAN.
 |
|
|---|---|
| Gemini Pro 1.5 | Sonnet 3.5 |
The code for this benchmark is here. It should be
easy to add support for additional models. You can read more about how answers are evaluated and questions are
vetted on the methodology page. If you have any questions, please contact me